Do we always assume that the function we use with knn is the euclidian distance in the exam ?
When should we use a different distance ?
Does KNN still work in high dimension ? I think that in theory no but in practice yes because there are some clusters but I would like to confirm.
Can we have some questions on the complexity of the training / testing ? If yes do we assume that nothing is optimized ? What would be the complexity ?
Is an evaluation by cross validation or train/test split still fiable ? I think it could negatively affect the result for a large K if we don't have much data.
Should we always normalize the data when we use a knn ?
Does the bound on the error that we had in lecture 4 still apply to KNN ?
Can we find the answer to this question:
Thank you
from :
and if yes how ? Because when I express n in terms of r I get :
N = log(1-p) / log(1-r^d)
Since log(1-r^d) is negative I intuitively think that log(1-(xr)^d) will decrease exponentially and will give N*x^d but can't prove it.
If f(x,y,z) = xyz and x=y=z. Can I consider the function equal to f(x) = x^3 and thus the derivative to be 3*x^2 ?
Is the complexity of the backpropagation of a CNN different from the one of a FFT? I think it would still be O(K²L) since we can approximate any CNN with an MLP but I don't know how the weight sharing affects the complexity.
What would be the complexity of a gradient update if we would not use backpropagation for a FFT ? I think it would be O(|W|K²L) with |W| the number of params as we would have to run some kind of back propagation for every weight.
Will a poor initialization of the weights affect a linear classifier with MSE or MAE ? A linear regression classifier ? A svm ? I think that they'll all converge to the same weights since they are strictly convex.
For a neural network, what is a good initialization of weights or a bad one ?
I'm a student so below are my educated guesses on your questions:
Do we always assume that the function we use with knn is the euclidian distance in the exam ?:
You don't have to assume this, it will probably be obvious.
When should we use a different distance ?: In non-euclidean cases, such as with textual data where you might use the edit-distance. Or in cases where the euclidean distance makes no sense for some reason.
Does KNN still work in high dimension ?: KNN works both in practice and in theory with any number of dimensions. However with more dimensions it will in at least in practice become a worse classifier/regressor because of the volume of data needed (it grows exponentially with number of dimensions).
Can we have some questions on the complexity...: Considering previous exams I am guessing yes. Optimization should not change the time complexity in our cases, otherwise it's another algorithm.
Is an evaluation by cross validation or train/test split still fiable ?: I am pretty sure you can use it to asses the model, however I am not sure personally how it generalizes to KNN. If I had to guess it's no difference to the other cases where we use CV.
Should we always normalize the data when we use a knn ?: I would say it's crucial to normalize in KNN since otherwise one dimension can penalize the distances unproportionally.
Does the bound on the error that we had in lecture 4 still apply to KNN ?: I don't know.
Exam Question 4: Consider having 1 dimension, we want to half the distance between points. Then we simply double the amount of data. Now consider 2 dimensions: We double it twice, 3 dimensions: double it three times. So the general solution must be 2^(D)*N.
If f(x,y,z) = xyz and...: Not sure what you mean here.
Is the complexity of the backpropagation of a CNN different from the one of a FFT? : I'm not sure about the complexity. However, the pro of using FFT is that it might be more convenient performing the filtering (convolutions) in the network. Although I am from a signal processing background, I am not completely sure how it extends to NN's. If you are given the FFT of the filters it should be faster than performing the convolution. Then again I am not sure how this generalizes to NN's.
What would be the complexity of a gradient...: I don't know/I don't understand your question.
Will a poor initialization of the weights affect a linear classifier with MSE or MAE ?: It will since these losses are convex wrt to the error, however I find it hard to see that it would be convex wrt weights in all cases, so yes initialization of weights will affect the trained model in both MSE and MAE cases.
For a neural network, what is a good initialization of weights or a bad one ?: I think this depends on what activation-function and loss-function you use. Usually you use a random initialization of weights.
I just have a few remarks. I think that MAE and MSE are convex w.r.t to the weights in the case of linear classifiers.
About the complexity without propagation, we have seen that we need backpropagation to avoid computing the gradient of each parameter one by one.
The backpropagation algorithm has a complexity of O(K²L) for a FFT, what about a cnn ?
For the exam it makes sense but I would like a result based on a formula we've seen.
For cross validation, imagine you have a dataset of 250 samples in D dimension and you use a 5 fold cross validation. Testing a classifier with K=5 or more will affect the error as we have only few data.
I think there are some data structure to optimize the complexity of knn in order to find which points are nearby without checking all the points.
Questions about KNN, weight sharing, NN...
Hi,
I have a lot of questions, sorry about this.
Do we always assume that the function we use with knn is the euclidian distance in the exam ?
When should we use a different distance ?
Does KNN still work in high dimension ? I think that in theory no but in practice yes because there are some clusters but I would like to confirm.
Can we have some questions on the complexity of the training / testing ? If yes do we assume that nothing is optimized ? What would be the complexity ?
Is an evaluation by cross validation or train/test split still fiable ? I think it could negatively affect the result for a large K if we don't have much data.
Should we always normalize the data when we use a knn ?
Does the bound on the error that we had in lecture 4 still apply to KNN ?
Can we find the answer to this question:
Thank you
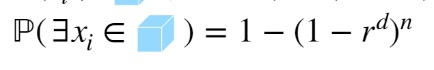
from :
and if yes how ? Because when I express n in terms of r I get :
N = log(1-p) / log(1-r^d)
Since log(1-r^d) is negative I intuitively think that log(1-(xr)^d) will decrease exponentially and will give N*x^d but can't prove it.
If f(x,y,z) = xyz and x=y=z. Can I consider the function equal to f(x) = x^3 and thus the derivative to be 3*x^2 ?
Is the complexity of the backpropagation of a CNN different from the one of a FFT? I think it would still be O(K²L) since we can approximate any CNN with an MLP but I don't know how the weight sharing affects the complexity.
What would be the complexity of a gradient update if we would not use backpropagation for a FFT ? I think it would be O(|W|K²L) with |W| the number of params as we would have to run some kind of back propagation for every weight.
Will a poor initialization of the weights affect a linear classifier with MSE or MAE ? A linear regression classifier ? A svm ? I think that they'll all converge to the same weights since they are strictly convex.
For a neural network, what is a good initialization of weights or a bad one ?
Thank you for your time
I'm a student so below are my educated guesses on your questions:
You don't have to assume this, it will probably be obvious.
4
Thank you for your answer.
I just have a few remarks. I think that MAE and MSE are convex w.r.t to the weights in the case of linear classifiers.
About the complexity without propagation, we have seen that we need backpropagation to avoid computing the gradient of each parameter one by one.
The backpropagation algorithm has a complexity of O(K²L) for a FFT, what about a cnn ?
For the exam it makes sense but I would like a result based on a formula we've seen.
For cross validation, imagine you have a dataset of 250 samples in D dimension and you use a 5 fold cross validation. Testing a classifier with K=5 or more will affect the error as we have only few data.
I think there are some data structure to optimize the complexity of knn in order to find which points are nearby without checking all the points.
Add comment