About the max -> min: indeed, a typo. Thanks for spotting it!
About the MLE vs. MAP: in this particular case, MLE and MAP coincide since \(p(\hat{y}=1)=p(\hat{y}=-1)=0.5\). But I'm not sure if it's a common convention to call it a MAP estimate in this context as we don't have any prior distribution on parameters here. Perhaps, just calling it a conditional probability would be better. But we'll check that, thanks!
Lecture 9c typo
Hi,
There is a typo in this slide :

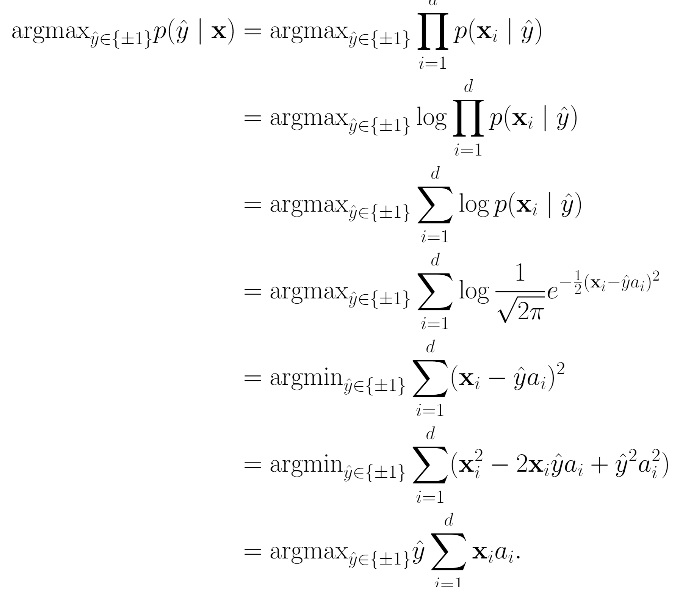
With the minus sign, arg max should become argmin like in the notes
Also, on the slide we minimize the MLE however in the notes we have a Bayes (=MAP) classifier.

Hi,
About the max -> min: indeed, a typo. Thanks for spotting it!
About the MLE vs. MAP: in this particular case, MLE and MAP coincide since \(p(\hat{y}=1)=p(\hat{y}=-1)=0.5\). But I'm not sure if it's a common convention to call it a MAP estimate in this context as we don't have any prior distribution on parameters here. Perhaps, just calling it a conditional probability would be better. But we'll check that, thanks!
Best,
Maksym
1
Add comment