I'm afraid I don't understand the word2vec algorithm. For the positive sampling do we just sample a word within window of 5 or do we carry training on all words within window of 5. When we sample for fake example is it across entire text or purely outside window of 5? And how many samples do we take for given word d. Do we carry this out sequentially for every word across a text?
In one of the past exam we were also supposed to know the step has same complexity as for GloVe I am not sure how we see this? I was under the impression word2vec was trained with a neural net, these can have quite higher complexity than a matrix factorization step I believe?
word2vec algorithm
Hello,
I'm afraid I don't understand the word2vec algorithm. For the positive sampling do we just sample a word within window of 5 or do we carry training on all words within window of 5. When we sample for fake example is it across entire text or purely outside window of 5? And how many samples do we take for given word d. Do we carry this out sequentially for every word across a text?
In one of the past exam we were also supposed to know the step has same complexity as for GloVe I am not sure how we see this? I was under the impression word2vec was trained with a neural net, these can have quite higher complexity than a matrix factorization step I believe?
Thank you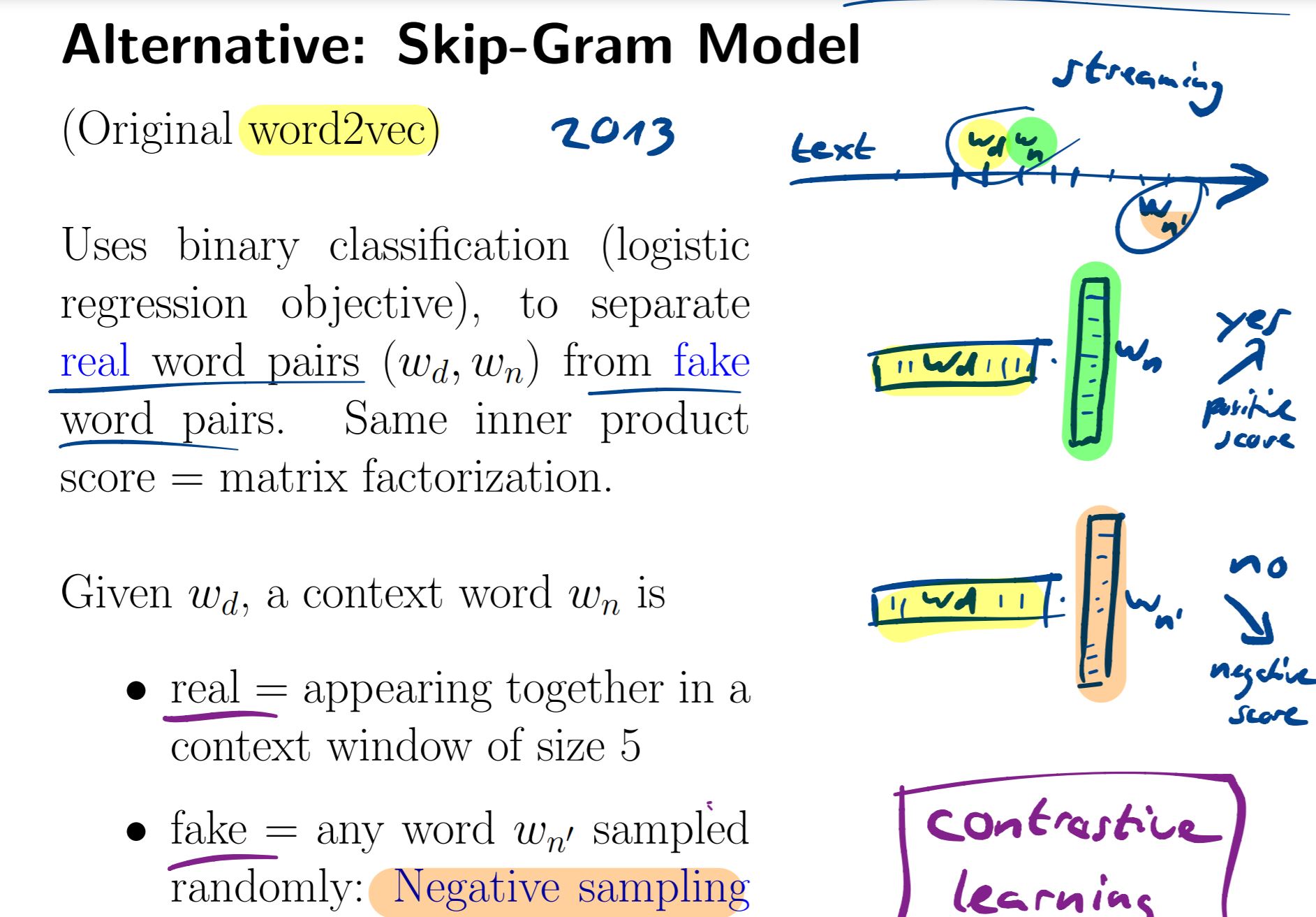
1
Add comment