Hello, I am having a slight issue regarding the effect that the outliers have on the model fitting. It doesn't seem that there is a large difference between the two, is anybody else experiencing a similar problem? I have that at times the fit looks better for the outlier case even. As an additional question, are we supposed to pick the last w obtained by the SGD method or the one pertaining to the lowest loss?
Outliners in Q5 do not differ too much from the rest of data for results to be too obvious. More different they are from the rest of datapoints, their effect will be more obvious. I got nice effects by changing load_data function in helpers.py a little bit (lines 25-28 in the original file):
I've tried this and I still can't see any visible effect. Just to clarify, we're supposed to standardize the data and then generate a w parameter using the SGD function two times (for normal data and outlier data), and then plot the regression lines for the models using the prediction() function, right?
Just to clarify, we're supposed to standardize the data and then generate a w parameter using the SGD function two times (for normal data and outlier data), and then plot the regression lines for the models using the prediction() function, right?
Right.
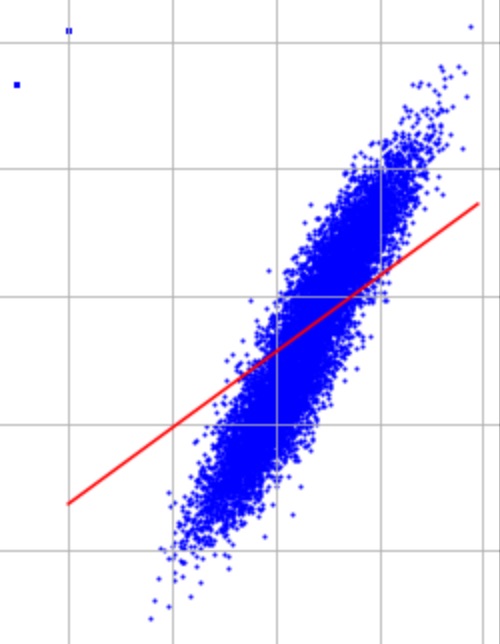
I have that at times the fit looks better for the outlier case even.
It's indeed hard to spot a difference since there are only 2 outliers and 10k normal points. To make the influence of the outliers more evident, you can modify the load_data function in the following way, i.e. by adding not 2 outliers, but 2 hundred outliers:
Then the fit will become clearly influenced by the outliers.
As an additional question, are we supposed to pick the last w obtained by the SGD method or the one pertaining to the lowest loss?
Obtaining the w with the lowest loss would be, of course, better from the optimization point of view. However, usually when SGD is used, it's often infeasible to compute the full training loss, i.e. instead we always work with small batches of the training data or in the extreme case only with batch size = 1. Taking the w with the lowest loss based only on, say, 1 example is extremely noisy, so it's rather recommended to take the last value of w or to take the average of the last values of w to reduce the variance.
Q5 Outliers (ex02)
Hello, I am having a slight issue regarding the effect that the outliers have on the model fitting. It doesn't seem that there is a large difference between the two, is anybody else experiencing a similar problem? I have that at times the fit looks better for the outlier case even. As an additional question, are we supposed to pick the last w obtained by the SGD method or the one pertaining to the lowest loss?
Outliners in Q5 do not differ too much from the rest of data for results to be too obvious. More different they are from the rest of datapoints, their effect will be more obvious. I got nice effects by changing load_data function in helpers.py a little bit (lines 25-28 in the original file):
1
I've tried this and I still can't see any visible effect. Just to clarify, we're supposed to standardize the data and then generate a w parameter using the SGD function two times (for normal data and outlier data), and then plot the regression lines for the models using the
prediction()function, right?Just to clarify, we're supposed to standardize the data and then generate a w parameter using the SGD function two times (for normal data and outlier data), and then plot the regression lines for the models using the prediction() function, right?Right.
I have that at times the fit looks better for the outlier case even.It's indeed hard to spot a difference since there are only 2 outliers and 10k normal points. To make the influence of the outliers more evident, you can modify the
load_datafunction in the following way, i.e. by adding not 2 outliers, but 2 hundred outliers:Then the fit will become clearly influenced by the outliers.
As an additional question, are we supposed to pick the last w obtained by the SGD method or the one pertaining to the lowest loss?Obtaining the w with the lowest loss would be, of course, better from the optimization point of view. However, usually when SGD is used, it's often infeasible to compute the full training loss, i.e. instead we always work with small batches of the training data or in the extreme case only with batch size = 1. Taking the w with the lowest loss based only on, say, 1 example is extremely noisy, so it's rather recommended to take the last value of w or to take the average of the last values of w to reduce the variance.
1
Add comment