Hello,
In the second question of Problem 3 (Proportional Hazard Model), in order to compute the joint probability of Y given the data, I don't see why we should introduce a whole vector y_tilde (defined using one hot encoding, as far as I understood) instead of just using the label y_n (an integer taking values in the set {1,2,..., K}) for each data point and compute the probability as the product (n: 1 -> N) of the given posterior distribution .
Thank you in advance !
Thanks for your answer, could you tell me which part of the lecture notes you are referring to ?
Because, for instance, when we showed that classic least-squares linear regression can be interpreted as a MLE (very beginning of the course) we didn't transform the labels into vectors for each data point or anything.
Mock Midterm 2017_Pb3_Q2
Hello,

In the second question of Problem 3 (Proportional Hazard Model), in order to compute the joint probability of Y given the data, I don't see why we should introduce a whole vector y_tilde (defined using one hot encoding, as far as I understood) instead of just using the label y_n (an integer taking values in the set {1,2,..., K}) for each data point and compute the probability as the product (n: 1 -> N) of the given posterior distribution .
Thank you in advance !
if you check the lecture notes, I believe it is a relatively common way to solve the problem.
Thanks for your answer, could you tell me which part of the lecture notes you are referring to ?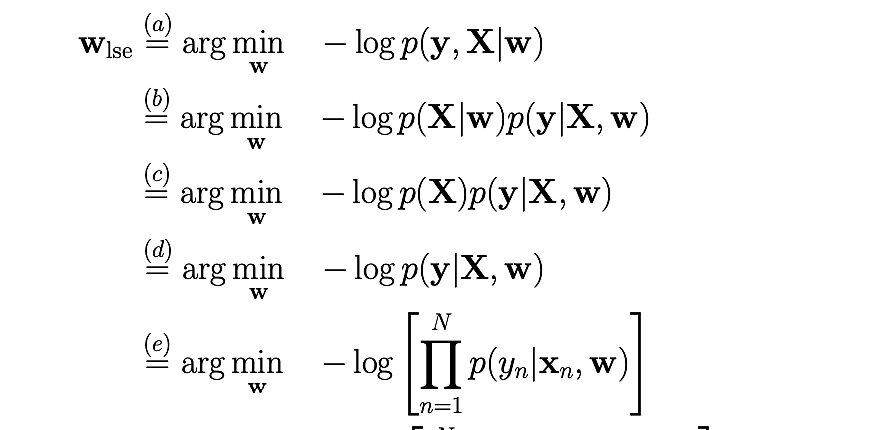
Because, for instance, when we showed that classic least-squares linear regression can be interpreted as a MLE (very beginning of the course) we didn't transform the labels into vectors for each data point or anything.
Add comment