training size and mode complexity - impact on error
Hello,
I understand that for high complexity it is easier to get closer to perfectly fitting a smaller amount of training point but how do we explain that initially the training error is lower for 100k, and what point does the transition represent.
I am also not exactly sure if the error is intrinsinc to the data how are we able to go below this threshold?
I have the same question. I can't figure out why the training error for 100k starts higher than the one for 5k.
I keep thinking it should be more or less "randomly equal" so maybe there is no point in doing that yellow transition?
Simple models
The more data we have the better we can generalize. This applies to simple models (little risk of overfitting) where it is easier to generalize with more data. Recall that simple models have high bias but that the more data, the smaller the bias is. Thus, with simpler models 100k train (more data) will have a smaller error than 5k train (less data).
Complex models
However, with more complex models it is easier to overfit less data than more. Again, complex models have higher variance and the less data the higher the variance. That is why, with more complex models, the loss of 5k train is lower than the loss of 100k train.
Imagine you have 5 points, a 4th order polynomial will give you a perfect fit (loss = 0). The same 4th order polynomial with 100 points will have a higher loss. Now imagine you have 100 points, in this case, you would need 99th order polynomial (much more complex model) in order to find a perfect fit.
I understand the explanation "simpler models 100k train (more data) will have a smaller error than 5k train (less data)." but isn't that relating to test error? The transition happens for training error, what is the reasoning there
I am not sue I agree with this though 'the more data, the smaller the bias is' : consider a sine curve approximated by a one parameter model f(x)= w0. You increase data means you just add more points to your data generating curve, the bias will not change and the average will stay around 0.
training size and mode complexity - impact on error
Hello,
I understand that for high complexity it is easier to get closer to perfectly fitting a smaller amount of training point but how do we explain that initially the training error is lower for 100k, and what point does the transition represent.
I am also not exactly sure if the error is intrinsinc to the data how are we able to go below this threshold?
thank you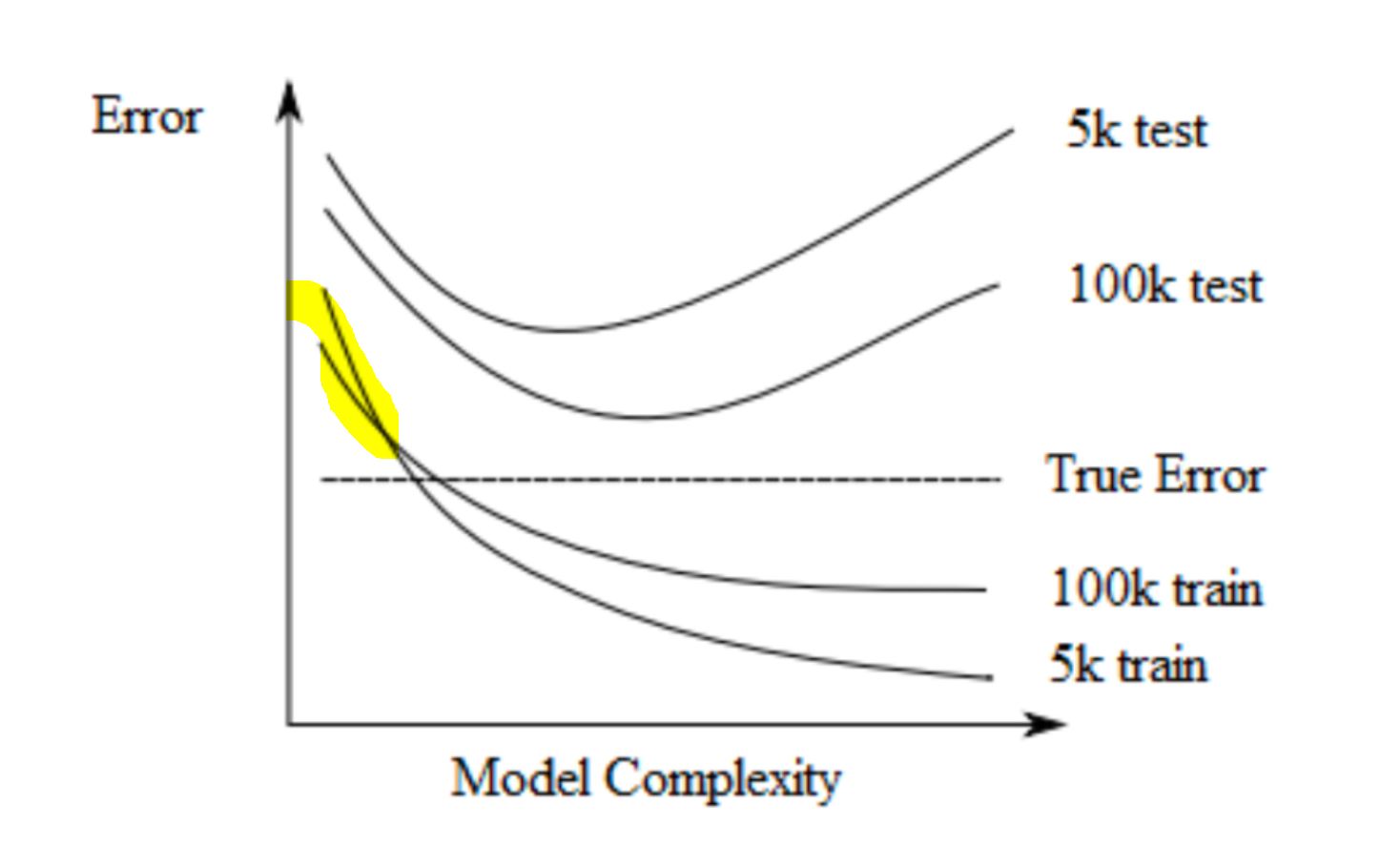
3
I have the same question. I can't figure out why the training error for 100k starts higher than the one for 5k.
I keep thinking it should be more or less "randomly equal" so maybe there is no point in doing that yellow transition?
thanks
Simple models
The more data we have the better we can generalize. This applies to simple models (little risk of overfitting) where it is easier to generalize with more data. Recall that simple models have high bias but that the more data, the smaller the bias is. Thus, with simpler models 100k train (more data) will have a smaller error than 5k train (less data).
Complex models
However, with more complex models it is easier to overfit less data than more. Again, complex models have higher variance and the less data the higher the variance. That is why, with more complex models, the loss of 5k train is lower than the loss of 100k train.
Imagine you have 5 points, a 4th order polynomial will give you a perfect fit (loss = 0). The same 4th order polynomial with 100 points will have a higher loss. Now imagine you have 100 points, in this case, you would need 99th order polynomial (much more complex model) in order to find a perfect fit.
2
Where does this plot come from ? I did not see it in the 2018 exam...
exam 2017
I understand the explanation "simpler models 100k train (more data) will have a smaller error than 5k train (less data)." but isn't that relating to test error? The transition happens for training error, what is the reasoning there
I am not sue I agree with this though 'the more data, the smaller the bias is' : consider a sine curve approximated by a one parameter model f(x)= w0. You increase data means you just add more points to your data generating curve, the bias will not change and the average will stay around 0.
2
Add comment