As he said, Scott will explain all the details in today solution session. But let me do a quick remark since this is far more general than SVM.
When you are considering a regularized objective your objective function is the sum of a function \(f\) and a regularization term \(R\) (which is also a function of your parameters, here \(R(w) = \|w\|_2^2\) ). And you are balancing this sum with a regularization parameter \( \lambda \).
If \( \lambda = 0\) then you are only minimizing the function \(f\) (the regularization disappears) and if \( \lambda = \infty\) then you are only minimizing the regularization term (the function \(f\) disappears from the objective). Then you will take a parameter \( \lambda \) which leads to a good tradeoff between the two terms (such as you are minimizing a little bit of both functions).
So why this is relevant to your question? Because the two problems you have written are very close: they just correspond to two problems with different regularization parameters.
hello, given the two problems are the same with a different regularization parameter: for the ex07 could we have minimized instead the left hand side and in that case there would have been no need to multiply the stochastic gradient by N? we would just have had to modify the lambda term correct?
Primal formula
Hi,
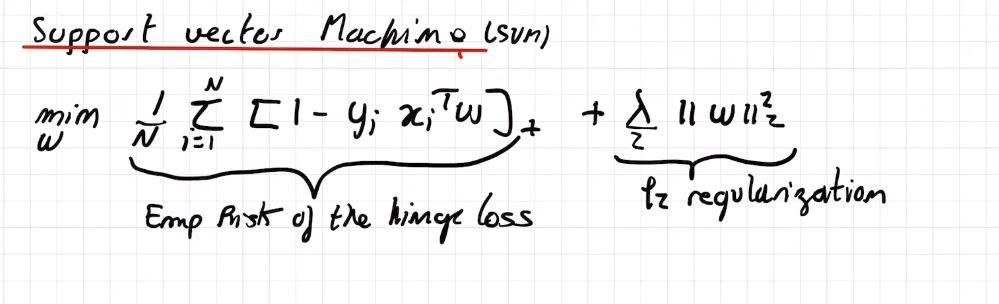
I don't understand why in the videos we've got this formula
And the course notes we've got this
This leads to "wrong" results in the code but also to quite some confusion...
I'm also a little confused as to why in the exercise we multiply the gradient by "num_features "
Thanks a lot for clarifying !
Waouh, sorry, quite a bug with my computer
Hello,
I invite you to come to the correction of the exercises on zoom this afternoon. All this should be made clear.
Best,
Scott
Hey,
As he said, Scott will explain all the details in today solution session. But let me do a quick remark since this is far more general than SVM.
When you are considering a regularized objective your objective function is the sum of a function \(f\) and a regularization term \(R\) (which is also a function of your parameters, here \(R(w) = \|w\|_2^2\) ). And you are balancing this sum with a regularization parameter \( \lambda \).
If \( \lambda = 0\) then you are only minimizing the function \(f\) (the regularization disappears) and if \( \lambda = \infty\) then you are only minimizing the regularization term (the function \(f\) disappears from the objective). Then you will take a parameter \( \lambda \) which leads to a good tradeoff between the two terms (such as you are minimizing a little bit of both functions).
So why this is relevant to your question? Because the two problems you have written are very close: they just correspond to two problems with different regularization parameters.
$$ \arg\min \frac{1}{N} \sum_{i=1}^N [ 1-y_i x_i^\top w]_+ + \frac{\lambda}{2} \|w\|_2^2 = \arg\min \sum_{i=1}^N [ 1-y_i x_i^\top w]_+ + \frac{\tilde \lambda}{2} \|w\|_2^2,$$
where \(\tilde \lambda = N\lambda \).
Best,
Nicolas
Waouh, good call !
Thanks for the clear explanation and the quick answer
1
hello, given the two problems are the same with a different regularization parameter: for the ex07 could we have minimized instead the left hand side and in that case there would have been no need to multiply the stochastic gradient by N? we would just have had to modify the lambda term correct?
1
Hi,
This is correct.
Best, Scott
1
Add comment